 21.01.2019
21.01.2019
22.03.2019
Science (Fiction) Breakthroughs and the Artificial Intelligence
Thanks to discoveries in physics and with advancements in technology, we are already able to build sensors and intelligent software capable of literally seeing the unseen, hearing the unheard and even seeing the unheard.
Blade Runner
In a certain scene from this classic released in 1982, an agent played by Harrison Ford uses his personal computer to zoom and enhance a photo. And no matter how deep he goes with the zoom, the machine never fails him. It always delivers a high resolution, sharp image of the area of interest. It can easily do that because they have 2019 there and obviously in such a distant future (37 years from the perspective of the movie creators), photos have infinite resolution. However amazing such a technological advancement might seem, there is a quite high chance you did not take it seriously. But when in the final glorious moment, you saw the machine looking around the corner of the pillar obstructing the view of the camera to reveal the lady behind I am sure, your slight disbelief must have turned into embarrassment or even pity.

Figure 1. Multiple zoom and enhance (top to center) and looking around the corner (center to bottom) in the scene from a movie “Blade Runner” (1982)
If this is how you felt, you should take a look at the paper Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network [Ledig, 2017] and realize that 2019 has not passed yet and we are already able to reconstruct details that seemingly cannot be captured by a camera due to its physical limitations.

Figure 2. Low resolution image (left), its deep-learning based super-resolution enhancement (center) and the real high-resolution photo (right). [images from the original paper]
How is this possible? How can the machine reconstruct such details if they were not captured in the original photo? First of all, to some extent, they were captured, but in a different way. Fine-grained patterns were entangled while spilling over the matrix of low-resolution pixels and although looking at an isolated pixel you can see nothing, when you look at its closest and farther neighbourhoods you might be able to untangle them back, at least with some degree of probability. For good results you need tremendous experience (read: a huge training set), the ability to deduce patterns at various scales (read: convolutional neural network), the ability to judge whether the produced patterns are reasonable (read: generative adversarial network) and a huge processing power to learn all that in a finite amount of time (read: GPU).
However, it was not the zoom and enhance that made you feel uncomfortable in that scene. It was the “seeing-around-corners” that you couldn’t take. If that is the case, take a look at Turning Corners Into Cameras [Bouman, 2017] and admire a technology in which cameras can actually trace objects far around the corner with centimetre level accuracy.
Figure 3. Although the camera seems to film nothing interesting, people walking far around the corner are influencing the light captured by the camera enough to track their position. [image from the original paper]
Harrison Ford could reproduce the entire look of the android lady around the corner in Blade Runner. Can we see faces of hidden people with this technology? Not yet, but fortunately, science still has a lot of time until the end of 2019.
Eagle Eye
How can you read the conversation of people behind a sound-proof glass if they had switched off all their electronic devices and turned around to hide their lips? Obviously from the reflection of water in a glass.
Is there anyone who took this seriously while watching this scene in Eagle Eye from 2008? Have a look at The Visual Microphone: Passive Recovery of Sound from Video [Davis, 2014] published just 6 years after this scene was filmed. It turns out that soundwaves physically hit delicate objects with enough force to make their movement visible to the camera. These micro-vibrations are at the level of a hundredth of a degree of a pixel, but with a camera capable of a high framerate, their frequency spectrum can be captured.
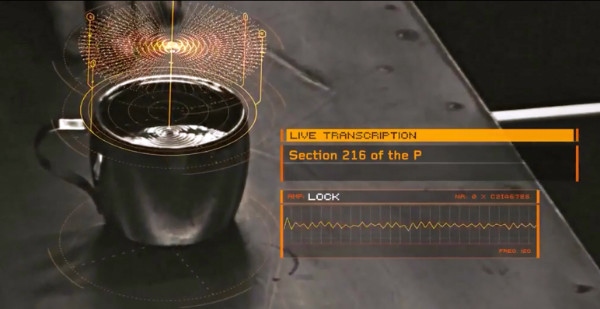
Figure 4. Reading voices from the vibrations of water in the sci-fi movie “Eagle Eye” (2008)
Thanks to discoveries in physics and with advancements in technology, we are already able to build sensors and intelligent software capable of literally seeing the unseen, hearing the unheard and even seeing the unheard. What else can we learn from a pack of crisps lying on the floor? The future will tell, but it seems there is no limit. In light of this, it is fun to speculate that every time you breathe in, it is highly probable that at least one of the molecules you inhale was actually exhaled by Julius Caesar in the throes of death. The question is what we can learn from this molecule and its context. Probably a lot. We just need better technology.

Figure 5. Reading voices (bottom-right) from the video of a pack of crisps (bottom left) in a real experiment (top). Hear it for yourself at youtu.be/FKXOucXB4a8
Knight Rider
If anyone were to own a talking car, it would have to be David Hasselhoff. But is the talking car really that extraordinary? Although text to speech synthesis has been with us for ages, making it indistinguishable from human speech is a scary advancement. Have a look at Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions [Shen, 2017] and the corresponding website and check if you can distinguish between a human and a machine.
However, Mr KITT is far more than text to speech synthesizer. It really knows WHAT it is talking about and it can describe the world it sees with its own words. If this seems a distant future for you, have a look at Deep Visual-Semantic Alignments for Generating Image Descriptions [Karpathy, 2015], where a machine is able to semantically segment an image and generate grammatically correct sentences to describe it. If this were not impressive enough, take a look at Generative Adversarial Text to Image Synthesis [Reed, 2015]. With this technology, you can talk to your computer, and it will imagine and draw photorealistic images matching your words.

Figure 5. Knight Rider’s Mr. KITT can now really analyze what it sees, formulate it into a sentence (image to text), say it out loud (text to speech) indistinguishably from a human being and even visually imagine what you are saying to it (speech to text to image)
Deep learning models, together with graph databases, are formulating the models of language and knowledge, models for understanding and expressing. Now, if we add all the recent advancements in self-driving by researchers from Nvidia [Bojarski, 2016], Waymo [Bansal, 2018], Tesla, Tomtom [Ghafoorian, 2018] and hundreds of other companies and institutions around the world, it is time to realize that Mr KITT is becoming a reality.
Mind Reader
Although there is a 1933 film with that title, it has nothing to do with technology. The closest we get to mind reading in recent science-fiction is in Avatar (2009) by James Cameron and Inception (2010) by Christopher Nolan.

Figure 6. Dream synchronizer from “Inception” movie, written, co-produced, and directed by Christopher Nolan, and co-produced by Emma Thomas- (top) and mind state transmitter from “Avatar”, written, produced, and co-edited by James Cameron (bottom).
Although the technologies presented here are not the main theme, they are rather the story igniters, could anyone take them seriously anyway? Well, it turns out someone is actually seriously thinking about letting machine see your thoughts. Take a look at End-to-end deep image reconstruction from human brain activity [Shen, 2018] and admire how a deep convolutional neural network is able to reproduce the image perceived by analyzing brain activity.

Figure 7. Test images shown to people (left) and their reconstructions from the brain activity (fMRI) analysis obtained by deep convolutional neural network (right). [image from the original paper]
The Terminator
Science-Fiction filmmakers are in trouble. We are entering interesting times, where the world of technological research runs so fast that it now takes longer to produce a reasonable science-fiction movie than to actually turn a futuristic vision into a reality. At the moment, with so many advancements in artificial intelligence, the most interesting question is whether we can we make machines conscious. Visionaries from around the world are throwing their deadlines for this to happen, while at the moment, no one is actually able to define what consciousness is in terms of science. It seems that consciousness is the last resort for our beloved science-fiction cinema and filmmakers have been doing their job well for many years with The Terminator (1984), The Matrix (1999), Ex Machina (2015) or the new “Blade Runner 2049” (2019) giving us thrilling visions of machines taking matters into their own hands. But, can anyone take it seriously?

The last figure. The terminator.
Tags:
See also:


LATEST NEWS
Od czego zależy sukces wdrożeń AI? - polskie i amerykańskie trendy w branży tech 24.10.2025
Five highlights from EU Space Days 2025 13.06.2025
🤝 Networking i zabawa na Infoshare 2025 30.04.2025
⭐ Spotkaj liderów innowacji | Keynote Speakers 23.04.2025
🎸 Zagraj na Great Networking Party | Call for Bands 16.04.2025
🏆 Gdańsk Startup Award – Twoja Szansa na Sukces! 09.04.2025